



A code agent harness is the set of rules, tools, and gates that turns an automated attempt into a reviewable PR. Code agents already write, edit, and open pull requests. The problem has shifted: the least useful question is "can the AI code?" and the most expensive one became "how do I know this PR can be reviewed without turning into an endless manual audit?".
In 2026, GitLab's AI Accountability Report states that 85% of developers point to reviewing, editing, and testing AI-generated code as the most time-consuming part of the workflow (GitLab, AI Accountability Report, 2026). The long-tail opportunity sits exactly there: a verification harness for code agents.
Quick summary
- The bottleneck moved from writing to PR review.
- A good harness limits scope, requires evidence, and runs gates before the human.
- MCP and subagents help when each tool has a clear contract.
- The goal is a small, traceable, testable PR.
Why do code agents need a harness?
In 2026, GitLab reports that 92% of organizations have already adopted AI governance controls, while 85% of developers still see review, editing, and testing as the bottleneck (GitLab, AI Accountability Report, 2026). The harness exists to convert speed into evidence before the human reviewer.
Without a harness, the agent makes a dangerous mix: it changes code, interprets tests, summarizes its own work, and asks for trust. That concentrates risk in a single narrative. With a harness, every step leaves an independent trail: plan, diff, tests, logs, scope limits, and the reason for any failure.
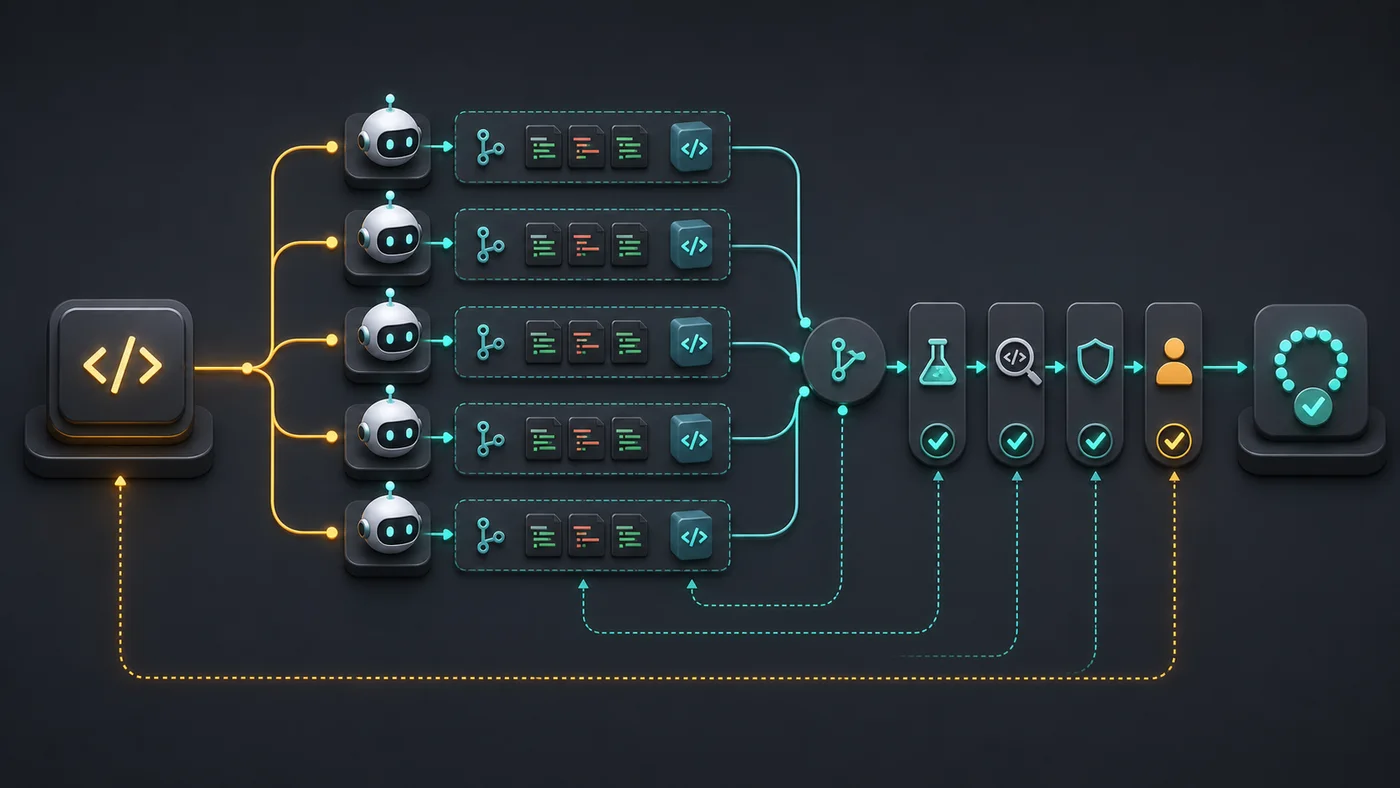
A good harness doesn't need to be big. It needs to be boring in the right way. It defines input, output, allowed tools, required commands, and the blocking criteria. The agent can suggest. The harness decides whether there is enough proof to continue.
Practical insight: treat the agent as a fast contributor, not as the owner of the merge. Speed shows up before trust. The harness closes that gap with checks that don't depend on the model's confident tone.
For baseline context, this blog already has posts on end-to-end testing with Playwright and the types of tests in software development. The difference here is treating those tests as an operational contract for agents.
What goes into the harness before the first diff?
In 2025, Stack Overflow showed that AI tool usage among developers stayed high, but trust in the accuracy of answers dropped to 29% (Stack Overflow, Developer Survey AI, 2025). That's why the harness should start before the diff: it reduces ambiguity before the agent writes any code.
The first block is the short spec. It states which behavior must change, which behavior must not change, which files are in scope, and what proof will be accepted. This looks like bureaucracy, but it avoids the most common form of waste: a correct PR for the wrong problem.
The second block is the risk inventory. If the task touches authentication, payment, personal data, migration, queues, or permissions, the harness needs to raise the bar. In those cases, a happy-path test isn't enough. The PR must prove the negative case, regression, and rollback.
The third block is the stop contract. When the agent hits a repeated failure, insufficient context, or a divergent environment, it must stop and declare a block. Autonomous loops that keep going without new evidence only accumulate noise.
| Harness input | Question it answers | Failure signal |
|---|---|---|
| Allowed scope | Where can the agent touch? | Files outside the limit show up in the diff. |
| Required proof | Which command validates the change? | The PR brings no verifiable output. |
| Invariants | What must not break? | Old tests disappear or get skipped. |
| Stop condition | When should the loop stop? | The agent retries with no new diagnosis. |
How does MCP change the harness design?
In 2024, Anthropic introduced the Model Context Protocol to standardize connections between models and external tools (Anthropic, Introducing the Model Context Protocol, 2024). In the 2025 specification, MCP organizes capabilities as tools, resources, and prompts (Model Context Protocol, specification, 2025). For code agents, this turns integration into a contract.
MCP doesn't make an agent safe on its own. It makes the boundary more explicit. A ticket-reading tool can be read-only. A CI tool can expose status, not secrets. A database tool can point to a development environment, not production.
The harness should treat each MCP server as a permission surface. The question is not "can the agent call the tool?". The right question is "what damage does this tool cause if the agent is wrong?". The contract comes from that answer.
For long tasks, context cost is also worth thinking about. When the loop has to switch between Codex, Claude Code, logs, diffs, and subagents, a tool like RemoteCode for scaling agentic workflows with less token waste comes in as the author's own resource to push these cycles further without pretending context cost doesn't exist.
Hands-on experience: I split tools into groups: read, propose, and change. Read tools can be broad. Tools that change state need a narrow scope, a verifiable environment, and a decision log. That simple split avoids a lot of confusion.
Where do subagents make sense in real PRs?
In 2026, the claude-blog README documents a pipeline with 30 sub-skills, 12 templates, 21 references, and a delivery contract with 5 gates that blocks drafts below 90/100 (AgriciDaniel, claude-blog, 2026). The lesson for code is direct: fan-out without a gate becomes dispersion; fan-out with a contract becomes parallel review.
Subagents work best when each one has a small role. One subagent can read tests. Another can review security. Another can look for impact on TypeScript types. Another can compare the spec against the diff. Mixing everything into the same agent reduces coordination cost, but it also reduces independence.
The harness needs to consolidate answers without turning opinions into truth. If the security subagent flags a risk, the PR must not hide that alert behind an optimistic summary. It should mark the finding, link it to the file, and require a human decision or an additional test.
flowchart LR
A[Small task] --> B[Implementer agent]
B --> C[Isolated diff]
C --> D[Tests]
C --> E[Security review]
C --> F[Type checking]
D --> G[Harness decides]
E --> G
F --> G
G --> H[PR with evidence]
The golden rule: a subagent doesn't replace a gate. It increases the observation surface. The gate stays responsible for blocking, requesting a new iteration, or releasing the PR for human review.
How do you build the self-correcting loop without self-deception?
In 2025, OpenAI described Codex as a cloud software engineering agent that works on tasks, runs commands in a sandbox, and returns evidence such as logs and test results (OpenAI, Introducing Codex, 2025). This format is strong because it separates editing from proof; the loop only matters when the proof is in charge.
An honest self-correcting loop has clear states. First, the agent tries a small change. Then, the harness runs the defined proof. Finally, the agent can only iterate if the failure brings new information. If the error hasn't changed, repeating just burns context.
The loop also needs short-term memory and long-term memory. Short-term memory holds the current error, the command that failed, and the diff that caused it. Long-term memory holds the repository's patterns: test style, canonical commands, external services, and known traps.
Don't confuse automatic correction with permission to touch everything. An agent that changes many files to pass a broken test may have increased risk, not reduced it. The harness should measure diff size, module boundary, and the relationship between the test and the requirement.
Which gates should block the PR?
In 2026, GitLab itself frames the problem as AI code being generated faster than organizations can control it (GitLab, AI Accountability Report, 2026). PR gates exist to flip that asymmetry: automation only speeds things up when it also produces control.
The first gate is reproduction. If it was a bug, the PR must show the test that failed before. If it was a feature, it must show the expected behavior and the negative boundary. Without that, the reviewer becomes a manual intent detector.
The second gate is diff integrity. The harness must block out-of-scope files, test removal without justification, and lockfile changes with no related dependency. This catches many a "solution" that only pushes the problem somewhere else.
The third gate is operational evidence. For backend, that can include a contract test, a reversible migration, structured logging, and a permission check. For DevOps, it can include an infrastructure plan, a rollback policy, and the absence of secrets in the diff.
<figure>
<svg viewBox="0 0 760 260" role="img" aria-label="Verification gates for code agent PRs">
<rect width="760" height="260" rx="18" fill="#101820"></rect>
<g font-family="Arial, sans-serif" font-size="18" fill="#f7f7f7">
<text x="48" y="54">Harness blocking flow</text>
<rect x="48" y="92" width="140" height="70" rx="10" fill="#1f6f78"></rect>
<text x="74" y="134">Scope</text>
<rect x="230" y="92" width="140" height="70" rx="10" fill="#2a8f7a"></rect>
<text x="255" y="134">Tests</text>
<rect x="412" y="92" width="140" height="70" rx="10" fill="#b77f2a"></rect>
<text x="436" y="134">Risk</text>
<rect x="594" y="92" width="118" height="70" rx="10" fill="#4f6f9f"></rect>
<text x="621" y="134">PR</text>
</g>
<g stroke="#e7f6f2" stroke-width="4" fill="none" stroke-linecap="round">
<path d="M188 127 H230"></path>
<path d="M370 127 H412"></path>
<path d="M552 127 H594"></path>
</g>
</svg>
<figcaption>Source: editorial synthesis based on the review contracts described in this article.</figcaption>
</figure>How does this become an engineering routine?
In 2025, Stack Overflow's survey showed broad AI adoption, but also a drop in trust in the accuracy of the tools (Stack Overflow, Developer Survey AI, 2025). A good routine accepts that tension: it uses agents to reduce repetitive work, but it requires evidence before accepting a change.
Start with one class of task. Small backend bugs are usually good candidates, because you can require a reproduction test. Then move on to localized refactors, observability improvements, and CI adjustments. Avoid starting with broad migrations or sensitive security rules.
The agent's instruction file must fit the team's real routine. It needs to say how to run tests, how to choose a file, how to report a block, and how to avoid out-of-scope changes. If nobody reviews that file, it becomes decoration.
It's also worth keeping a short log per PR. Not for bureaucracy. For learning. Which failures did the harness catch? Which slipped through? What turned into a false positive? What should have blocked and didn't? That history improves the harness without relying on informal memory.
FAQ on code agent harnesses
Does a code agent harness replace human code review?
No. In 2026, GitLab shows that 85% of developers see reviewing, editing, and testing AI code as the bottleneck (GitLab, AI Accountability Report, 2026). The harness reduces noise before the human, but product, security, and architecture decisions stay human.
Is MCP required for this kind of workflow?
No, but it helps when the agent needs to access heterogeneous tools. In 2025, the Model Context Protocol specification describes tools, resources, and prompts as standardized parts of the contract (Model Context Protocol, specification, 2025). Without MCP, the same principle holds: every tool needs clear permission and proof.
Which gate is worth implementing first?
Start with a reproduction test. In 2025, Stack Overflow showed that trust in the accuracy of AI answers stood at 29% (Stack Overflow, Developer Survey AI, 2025). A test that fails before and passes after reduces subjective debate over whether the agent understood the problem.
Do subagents always improve the result?
No. In 2026, claude-blog only makes fan-out productive because it combines sub-skills with a delivery contract, blocking review, and an iteration limit (AgriciDaniel, claude-blog, 2026). In code, subagents without a gate create more opinions to review.
Sources and further reading
- GitLab, AI Accountability Report, retrieved 2026-06-28, https://ir.gitlab.com/news/news-details/2026/GitLab-Research-Reveals-Organizations-Are-Generating-AI-Code-Faster-Than-They-Can-Control-It/default.aspx
- Stack Overflow, Developer Survey AI, retrieved 2026-06-28, https://survey.stackoverflow.co/2025/ai/
- Anthropic, Introducing the Model Context Protocol, retrieved 2026-06-28, https://www.anthropic.com/news/model-context-protocol
- Model Context Protocol, specification 2025-06-18, retrieved 2026-06-28, https://modelcontextprotocol.io/specification/2025-06-18/
- OpenAI, Introducing Codex, retrieved 2026-06-28, https://openai.com/index/introducing-codex/
- AgriciDaniel, claude-blog, retrieved 2026-06-28, https://github.com/AgriciDaniel/claude-blog


