



Harness de agentes de código é o conjunto de regras, ferramentas e gates que transforma uma tentativa automática em um PR revisável. Agentes de código já escrevem, editam e abrem pull requests. O problema mudou: a pergunta menos útil é "a IA consegue codar?" e a pergunta mais cara virou "como eu sei que esse PR pode ser revisado sem virar uma auditoria manual infinita?".
Em 2026, o relatório AI Accountability da GitLab afirma que 85% dos desenvolvedores apontam revisar, editar e testar código gerado por IA como a parte mais demorada do fluxo (GitLab, AI Accountability Report, 2026). A oportunidade long tail está exatamente aí: um harness de verificação para agentes de código.
Resumo prático
- O gargalo saiu da escrita e foi para a revisão do PR.
- Um harness bom limita escopo, exige evidência e roda gates antes do humano.
- MCP e subagentes ajudam quando cada ferramenta tem contrato claro.
- O objetivo é PR pequeno, rastreável e testável.
Por que agentes de código precisam de harness?
Em 2026, a GitLab relata que 92% das organizações já adotaram controles de governança para IA, enquanto 85% dos desenvolvedores ainda veem revisão, edição e teste como gargalo (GitLab, AI Accountability Report, 2026). O harness existe para converter velocidade em evidência antes do reviewer humano.
Sem harness, o agente faz uma mistura perigosa: muda código, interpreta testes, resume o próprio trabalho e pede confiança. Isso concentra risco em uma narrativa só. Com harness, cada etapa deixa um rastro independente: plano, diff, testes, logs, limites de escopo e motivo de qualquer falha.
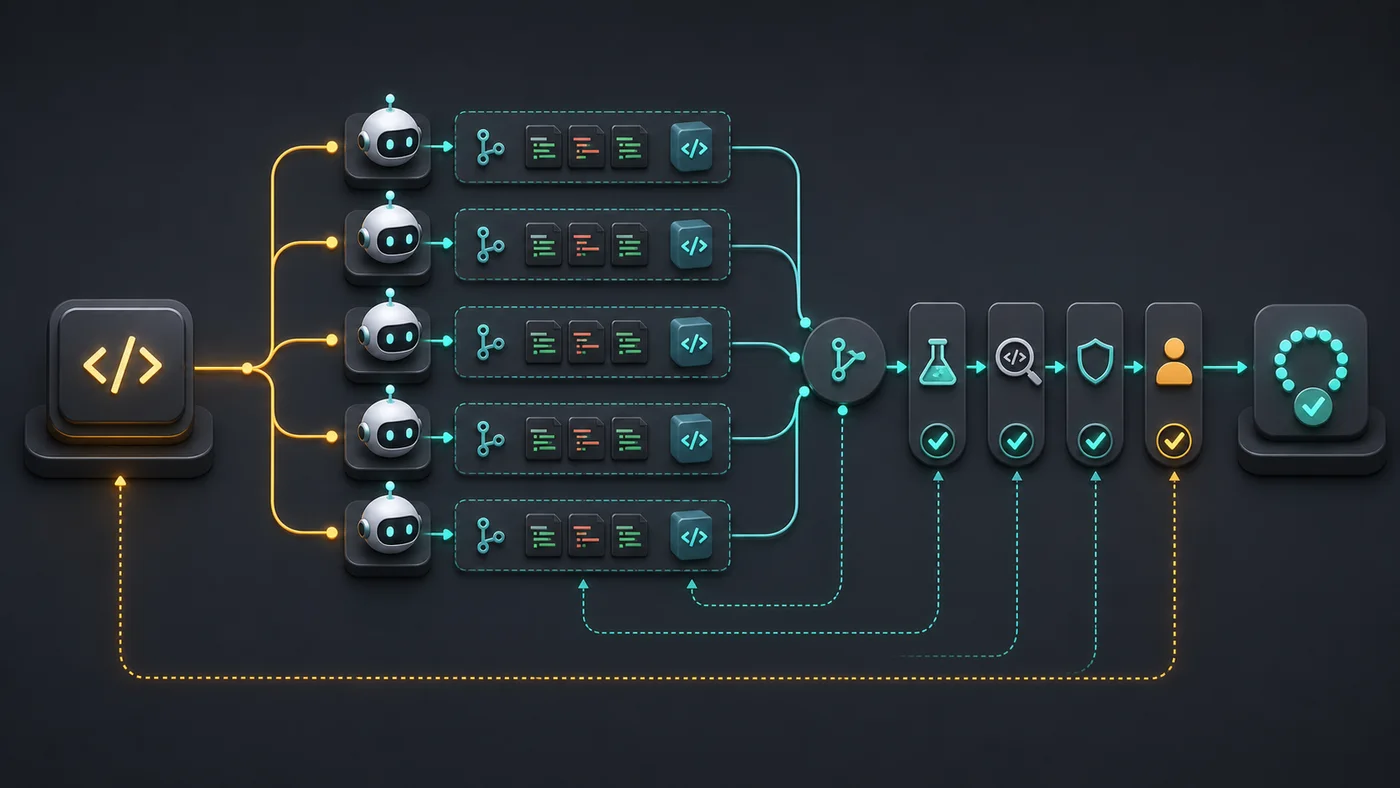
Um bom harness não precisa ser grande. Ele precisa ser chato do jeito certo. Define entrada, saída, ferramentas permitidas, comandos obrigatórios e critério de bloqueio. O agente pode sugerir. O harness decide se há prova suficiente para continuar.
Insight prático: trate o agente como um contribuinte rápido, não como dono do merge. A velocidade aparece antes da confiança. O harness fecha esse intervalo com verificações que não dependem do tom confiante do modelo.
Para contexto de base, este blog já tem textos sobre testes end-to-end com Playwright e tipos de testes em desenvolvimento de software. A diferença aqui é colocar esses testes como contrato operacional para agentes.
O que entra no harness antes do primeiro diff?
Em 2025, a Stack Overflow mostrou que o uso de ferramentas de IA entre desenvolvedores continuou alto, mas a confiança na precisão das respostas caiu para 29% (Stack Overflow, Developer Survey AI, 2025). Por isso, o harness deve começar antes do diff: ele reduz ambiguidade antes que o agente escreva código.
O primeiro bloco é a especificação curta. Ela diz qual comportamento deve mudar, qual comportamento não pode mudar, quais arquivos estão dentro do escopo e qual prova será aceita. Isso parece burocracia, mas evita a forma mais comum de desperdício: PR correto para o problema errado.
O segundo bloco é o inventário de risco. Se a tarefa toca autenticação, pagamento, dados pessoais, migração, fila ou permissão, o harness precisa aumentar a exigência. Nesses casos, teste feliz não basta. O PR deve provar negativa, regressão e rollback.
O terceiro bloco é o contrato de parada. Quando o agente encontra falha repetida, contexto insuficiente ou ambiente divergente, ele deve parar e declarar bloqueio. Loops autônomos que continuam sem nova evidência só acumulam ruído.
| Entrada do harness | Pergunta que ela responde | Sinal de falha |
|---|---|---|
| Escopo permitido | Onde o agente pode mexer? | Arquivos fora do limite aparecem no diff. |
| Prova obrigatória | Que comando valida a mudança? | O PR não traz saída verificável. |
| Invariantes | O que não pode quebrar? | Testes antigos somem ou ficam ignorados. |
| Condição de parada | Quando o loop deve parar? | O agente repete tentativa sem diagnóstico novo. |
Como MCP muda o desenho do harness?
Em 2024, a Anthropic apresentou o Model Context Protocol para padronizar conexões entre modelos e ferramentas externas (Anthropic, Introducing the Model Context Protocol, 2024). Na especificação de 2025, MCP organiza capacidades como ferramentas, recursos e prompts (Model Context Protocol, specification, 2025). Para agentes de código, isso transforma integração em contrato.
MCP não deixa um agente seguro por si só. Ele deixa o limite mais explícito. Uma ferramenta de leitura de tickets pode ser somente leitura. Uma ferramenta de CI pode expor status, não segredos. Uma ferramenta de banco pode apontar para ambiente de desenvolvimento, não produção.
O harness deve tratar cada servidor MCP como uma superfície de permissão. A pergunta não é "o agente consegue chamar a ferramenta?". A pergunta certa é "qual dano essa ferramenta causa se o agente estiver errado?". O contrato vem dessa resposta.
Para tarefas longas, também vale pensar em custo de contexto. Quando o loop precisa alternar entre Codex, Claude Code, logs, diffs e subagentes, uma ferramenta como RemoteCode para ampliar fluxos agentic com menos desperdício de tokens entra como recurso do próprio autor para empurrar esses ciclos mais longe sem fingir que custo de contexto não existe.
Experiência prática: eu separo ferramentas em grupos: ler, propor e alterar. Ferramentas de leitura podem ser amplas. Ferramentas que alteram estado precisam de escopo estreito, ambiente verificável e log de decisão. Essa divisão simples evita muita confusão.
Onde subagentes fazem sentido em PRs reais?
Em 2026, o README do claude-blog documenta um pipeline com 30 sub-skills, 12 templates, 21 referências e um contrato de entrega com 5 gates que bloqueia rascunhos abaixo de 90/100 (AgriciDaniel, claude-blog, 2026). A lição para código é direta: fan-out sem gate vira dispersão; fan-out com contrato vira revisão paralela.
Subagentes funcionam melhor quando cada um tem uma função pequena. Um subagente pode ler testes. Outro pode revisar segurança. Outro pode procurar impacto em tipos TypeScript. Outro pode comparar a especificação com o diff. Misturar tudo no mesmo agente reduz custo de coordenação, mas também reduz independência.
O harness precisa consolidar respostas sem transformar opiniões em verdade. Se o subagente de segurança alerta risco, o PR não deve esconder esse alerta num resumo otimista. Ele deve marcar o achado, ligar ao arquivo e exigir decisão humana ou teste adicional.
flowchart LR
A[Tarefa pequena] --> B[Agente implementador]
B --> C[Diff isolado]
C --> D[Testes]
C --> E[Revisão de segurança]
C --> F[Checagem de tipos]
D --> G[Harness decide]
E --> G
F --> G
G --> H[PR com evidência]
A regra de ouro: subagente não substitui gate. Ele aumenta a superfície de observação. O gate continua responsável por bloquear, pedir nova iteração ou liberar o PR para revisão humana.
Como montar o loop self-correcting sem autoengano?
Em 2025, a OpenAI descreveu Codex como um agente de engenharia de software em nuvem que trabalha em tarefas, roda comandos em sandbox e retorna evidências como logs e resultados de teste (OpenAI, Introducing Codex, 2025). Esse formato é forte porque separa edição de prova; o loop só vale quando a prova manda.
Um loop self-correcting honesto tem estados claros. Primeiro, o agente tenta uma mudança pequena. Depois, o harness roda a prova definida. Por fim, o agente só pode iterar se a falha trouxer informação nova. Se o erro não mudou, repetir é só queimar contexto.
O loop também precisa de memória curta e memória longa. A memória curta guarda o erro atual, o comando que falhou e o diff que o causou. A memória longa guarda padrões do repositório: estilo de teste, comandos canônicos, serviços externos e armadilhas conhecidas.
Não confunda correção automática com permissão para mexer em tudo. Um agente que altera muitos arquivos para passar um teste quebrado pode ter aumentado o risco, não reduzido. O harness deve medir tamanho do diff, fronteira de módulo e relação entre teste e requisito.
Quais gates devem bloquear o PR?
Em 2026, a própria GitLab enquadra o problema como código de IA sendo gerado mais rápido do que as organizações conseguem controlar (GitLab, AI Accountability Report, 2026). Gates de PR existem para inverter essa assimetria: a automação só acelera quando também produz controle.
O primeiro gate é reprodução. Se era bug, o PR deve mostrar o teste que falhava antes. Se era feature, deve mostrar comportamento esperado e limite negativo. Sem isso, o reviewer vira detector manual de intenção.
O segundo gate é integridade do diff. O harness deve bloquear arquivo fora de escopo, remoção de teste sem justificativa e mudança em lockfile sem dependência relacionada. Isso pega muita "solução" que apenas empurra problema para outro lugar.
O terceiro gate é evidência operacional. Para backend, isso pode incluir teste de contrato, migração reversível, log estruturado e verificação de permissão. Para DevOps, pode incluir plano de infraestrutura, política de rollback e ausência de segredo no diff.
<figure>
<svg viewBox="0 0 760 260" role="img" aria-label="Gates de verificação para PRs de agentes de código">
<rect width="760" height="260" rx="18" fill="#101820"></rect>
<g font-family="Arial, sans-serif" font-size="18" fill="#f7f7f7">
<text x="48" y="54">Fluxo de bloqueio do harness</text>
<rect x="48" y="92" width="140" height="70" rx="10" fill="#1f6f78"></rect>
<text x="74" y="134">Escopo</text>
<rect x="230" y="92" width="140" height="70" rx="10" fill="#2a8f7a"></rect>
<text x="255" y="134">Testes</text>
<rect x="412" y="92" width="140" height="70" rx="10" fill="#b77f2a"></rect>
<text x="436" y="134">Risco</text>
<rect x="594" y="92" width="118" height="70" rx="10" fill="#4f6f9f"></rect>
<text x="621" y="134">PR</text>
</g>
<g stroke="#e7f6f2" stroke-width="4" fill="none" stroke-linecap="round">
<path d="M188 127 H230"></path>
<path d="M370 127 H412"></path>
<path d="M552 127 H594"></path>
</g>
</svg>
<figcaption>Fonte: síntese editorial baseada nos contratos de revisão descritos neste artigo.</figcaption>
</figure>Como isso vira rotina de engenharia?
Em 2025, a pesquisa da Stack Overflow mostrou adoção ampla de IA, mas também queda de confiança na precisão das ferramentas (Stack Overflow, Developer Survey AI, 2025). A rotina boa aceita essa tensão: usa agentes para reduzir trabalho repetitivo, mas exige evidência antes de aceitar mudança.
Comece por uma classe de tarefa. Bugs pequenos de backend costumam ser bons candidatos, porque é possível exigir teste de reprodução. Depois avance para refactors localizados, melhorias de observabilidade e ajustes de CI. Evite começar por migração ampla ou regra de segurança sensível.
O arquivo de instrução do agente deve caber na rotina real do time. Ele precisa dizer como rodar testes, como escolher arquivo, como reportar bloqueio e como evitar mudanças fora de escopo. Se ninguém revisa esse arquivo, ele vira decoração.
Também vale registrar um diário curto por PR. Não para burocracia. Para aprendizado. Quais falhas o harness pegou? Quais passaram? O que virou falso positivo? O que deveria ter bloqueado e não bloqueou? Esse histórico melhora o harness sem depender de memória informal.
FAQ sobre harness de agentes de código
Harness de agente de código substitui code review humano?
Não. Em 2026, a GitLab mostra que 85% dos desenvolvedores veem revisão, edição e teste de código com IA como gargalo (GitLab, AI Accountability Report, 2026). O harness reduz ruído antes do humano, mas decisões de produto, segurança e arquitetura continuam humanas.
MCP é obrigatório para esse tipo de fluxo?
Não, mas ajuda quando o agente precisa acessar ferramentas heterogêneas. Em 2025, a especificação do Model Context Protocol descreve ferramentas, recursos e prompts como partes padronizadas do contrato (Model Context Protocol, specification, 2025). Sem MCP, o mesmo princípio vale: cada ferramenta precisa de permissão e prova claras.
Qual é o primeiro gate que vale implementar?
Comece por teste de reprodução. Em 2025, a Stack Overflow mostrou que a confiança na precisão das respostas de IA ficou em 29% (Stack Overflow, Developer Survey AI, 2025). Um teste que falha antes e passa depois reduz debate subjetivo sobre se o agente entendeu o problema.
Subagentes sempre melhoram o resultado?
Não. Em 2026, o claude-blog só torna fan-out produtivo porque combina sub-skills com contrato de entrega, revisão bloqueante e limite de iteração (AgriciDaniel, claude-blog, 2026). Em código, subagentes sem gate criam mais opiniões para revisar.
Fontes e leitura adicional
- GitLab, AI Accountability Report, retrieved 2026-06-28, https://ir.gitlab.com/news/news-details/2026/GitLab-Research-Reveals-Organizations-Are-Generating-AI-Code-Faster-Than-They-Can-Control-It/default.aspx
- Stack Overflow, Developer Survey AI, retrieved 2026-06-28, https://survey.stackoverflow.co/2025/ai/
- Anthropic, Introducing the Model Context Protocol, retrieved 2026-06-28, https://www.anthropic.com/news/model-context-protocol
- Model Context Protocol, specification 2025-06-18, retrieved 2026-06-28, https://modelcontextprotocol.io/specification/2025-06-18/
- OpenAI, Introducing Codex, retrieved 2026-06-28, https://openai.com/index/introducing-codex/
- AgriciDaniel, claude-blog, retrieved 2026-06-28, https://github.com/AgriciDaniel/claude-blog


