



El harness de agentes de código es el conjunto de reglas, herramientas y gates que convierte un intento automático en un PR revisable. Los agentes de código ya escriben, editan y abren pull requests. El problema cambió: la pregunta menos útil es «¿la IA sabe programar?» y la pregunta más cara pasó a ser «¿cómo sé que este PR se puede revisar sin convertirse en una auditoría manual infinita?».
En 2026, el informe AI Accountability de GitLab afirma que el 85% de los desarrolladores señala revisar, editar y probar código generado por IA como la parte más lenta del flujo (GitLab, AI Accountability Report, 2026). La oportunidad long tail está justo ahí: un harness de verificación para agentes de código.
Resumen práctico
- El cuello de botella pasó de la escritura a la revisión del PR.
- Un buen harness limita el alcance, exige evidencia y ejecuta gates antes del humano.
- MCP y subagentes ayudan cuando cada herramienta tiene un contrato claro.
- El objetivo es un PR pequeño, rastreable y verificable.
¿Por qué los agentes de código necesitan un harness?
En 2026, GitLab reporta que el 92% de las organizaciones ya adoptó controles de gobernanza para la IA, mientras que el 85% de los desarrolladores todavía ve la revisión, la edición y las pruebas como cuello de botella (GitLab, AI Accountability Report, 2026). El harness existe para convertir velocidad en evidencia antes del revisor humano.
Sin harness, el agente hace una mezcla peligrosa: cambia código, interpreta pruebas, resume su propio trabajo y pide confianza. Eso concentra el riesgo en una sola narrativa. Con harness, cada etapa deja un rastro independiente: plan, diff, pruebas, logs, límites de alcance y el motivo de cualquier falla.
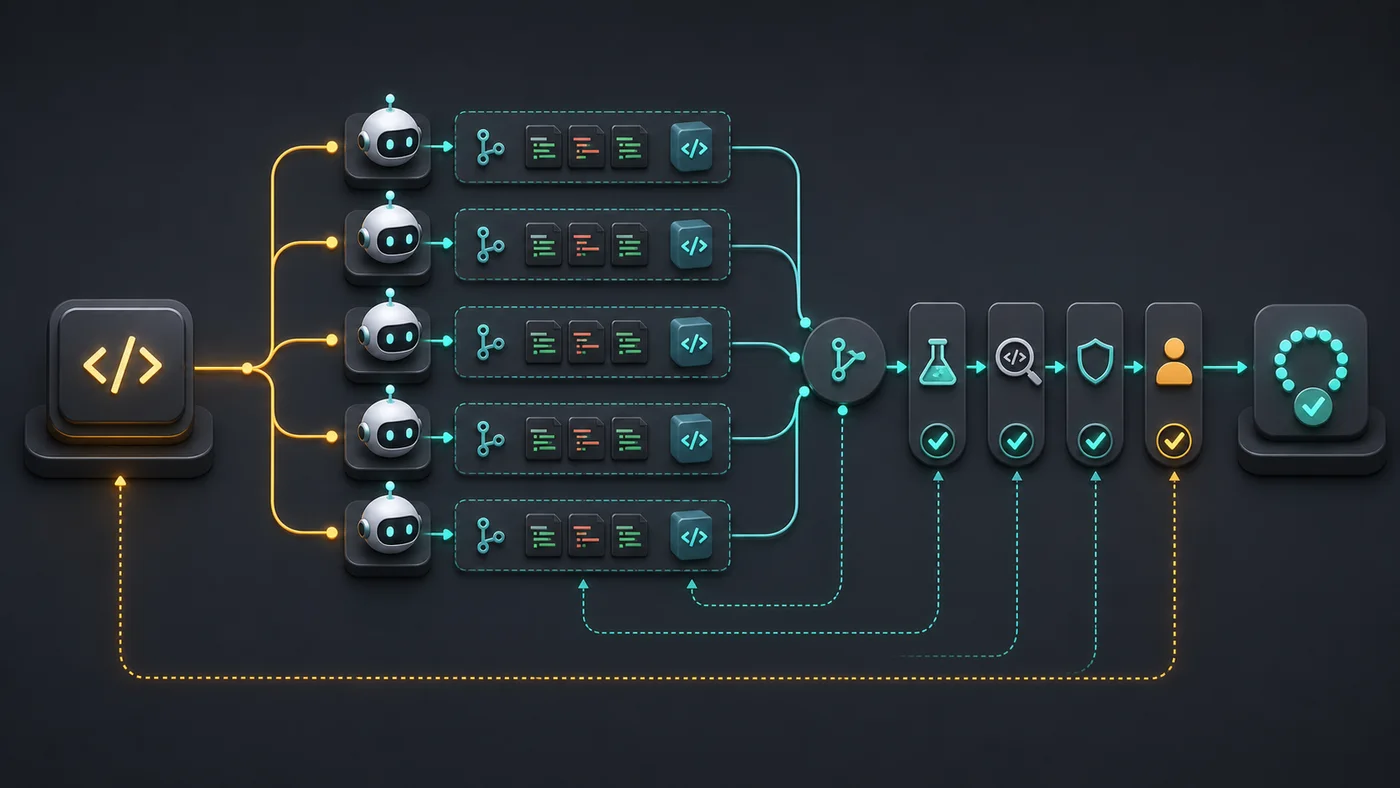
Un buen harness no necesita ser grande. Necesita ser estricto en el buen sentido. Define entrada, salida, herramientas permitidas, comandos obligatorios y criterio de bloqueo. El agente puede sugerir. El harness decide si hay prueba suficiente para continuar.
Insight práctico: trata al agente como un colaborador rápido, no como dueño del merge. La velocidad aparece antes que la confianza. El harness cierra esa brecha con verificaciones que no dependen del tono seguro del modelo.
Para contexto de base, este blog ya tiene textos sobre pruebas end-to-end con Playwright y tipos de pruebas en el desarrollo de software. La diferencia aquí es poner esas pruebas como contrato operativo para los agentes.
¿Qué entra en el harness antes del primer diff?
En 2025, Stack Overflow mostró que el uso de herramientas de IA entre desarrolladores se mantuvo alto, pero la confianza en la precisión de las respuestas cayó al 29% (Stack Overflow, Developer Survey AI, 2025). Por eso, el harness debe empezar antes del diff: reduce la ambigüedad antes de que el agente escriba código.
El primer bloque es la especificación corta. Indica qué comportamiento debe cambiar, qué comportamiento no puede cambiar, qué archivos están dentro del alcance y qué prueba se aceptará. Esto parece burocracia, pero evita la forma más común de desperdicio: un PR correcto para el problema equivocado.
El segundo bloque es el inventario de riesgo. Si la tarea toca autenticación, pago, datos personales, migración, cola o permisos, el harness debe subir la exigencia. En esos casos, una prueba del camino feliz no basta. El PR debe demostrar el caso negativo, la regresión y el rollback.
El tercer bloque es el contrato de parada. Cuando el agente encuentra una falla repetida, contexto insuficiente o un entorno divergente, debe detenerse y declarar bloqueo. Los loops autónomos que continúan sin evidencia nueva solo acumulan ruido.
| Entrada del harness | Pregunta que responde | Señal de falla |
|---|---|---|
| Alcance permitido | ¿Dónde puede intervenir el agente? | Aparecen archivos fuera del límite en el diff. |
| Prueba obligatoria | ¿Qué comando valida el cambio? | El PR no trae salida verificable. |
| Invariantes | ¿Qué no puede romperse? | Pruebas antiguas desaparecen o quedan ignoradas. |
| Condición de parada | ¿Cuándo debe detenerse el loop? | El agente repite el intento sin un diagnóstico nuevo. |
¿Cómo cambia MCP el diseño del harness?
En 2024, Anthropic presentó el Model Context Protocol para estandarizar conexiones entre modelos y herramientas externas (Anthropic, Introducing the Model Context Protocol, 2024). En la especificación de 2025, MCP organiza capacidades como herramientas, recursos y prompts (Model Context Protocol, specification, 2025). Para los agentes de código, esto convierte la integración en un contrato.
MCP no vuelve seguro a un agente por sí solo. Hace que el límite sea más explícito. Una herramienta de lectura de tickets puede ser de solo lectura. Una herramienta de CI puede exponer estado, no secretos. Una herramienta de base de datos puede apuntar al entorno de desarrollo, no a producción.
El harness debe tratar cada servidor MCP como una superficie de permisos. La pregunta no es «¿el agente puede llamar a la herramienta?». La pregunta correcta es «¿qué daño causa esa herramienta si el agente se equivoca?». El contrato sale de esa respuesta.
Para tareas largas, también conviene pensar en el costo de contexto. Cuando el loop necesita alternar entre Codex, Claude Code, logs, diffs y subagentes, una herramienta como RemoteCode para ampliar flujos agentic con menos desperdicio de tokens entra como recurso del propio autor para llevar esos ciclos más lejos sin fingir que el costo de contexto no existe.
Experiencia práctica: yo separo las herramientas en grupos: leer, proponer y modificar. Las herramientas de lectura pueden ser amplias. Las herramientas que modifican estado necesitan un alcance estrecho, un entorno verificable y un log de decisión. Esa división simple evita mucha confusión.
¿Dónde tienen sentido los subagentes en PRs reales?
En 2026, el README de claude-blog documenta un pipeline con 30 sub-skills, 12 plantillas, 21 referencias y un contrato de entrega con 5 gates que bloquea borradores por debajo de 90/100 (AgriciDaniel, claude-blog, 2026). La lección para el código es directa: un fan-out sin gate se vuelve dispersión; un fan-out con contrato se vuelve revisión paralela.
Los subagentes funcionan mejor cuando cada uno tiene una función pequeña. Un subagente puede leer pruebas. Otro puede revisar la seguridad. Otro puede buscar impacto en los tipos de TypeScript. Otro puede comparar la especificación con el diff. Mezclar todo en el mismo agente reduce el costo de coordinación, pero también reduce la independencia.
El harness debe consolidar respuestas sin convertir opiniones en verdad. Si el subagente de seguridad alerta sobre un riesgo, el PR no debe ocultar esa alerta en un resumen optimista. Debe marcar el hallazgo, vincularlo al archivo y exigir una decisión humana o una prueba adicional.
flowchart LR
A[Tarea pequeña] --> B[Agente implementador]
B --> C[Diff aislado]
C --> D[Pruebas]
C --> E[Revisión de seguridad]
C --> F[Chequeo de tipos]
D --> G[El harness decide]
E --> G
F --> G
G --> H[PR con evidencia]
La regla de oro: un subagente no sustituye a un gate. Aumenta la superficie de observación. El gate sigue siendo responsable de bloquear, pedir una nueva iteración o liberar el PR para revisión humana.
¿Cómo armar el loop self-correcting sin autoengaño?
En 2025, OpenAI describió Codex como un agente de ingeniería de software en la nube que trabaja en tareas, ejecuta comandos en un sandbox y devuelve evidencias como logs y resultados de pruebas (OpenAI, Introducing Codex, 2025). Ese formato es fuerte porque separa la edición de la prueba; el loop solo vale cuando manda la prueba.
Un loop self-correcting honesto tiene estados claros. Primero, el agente intenta un cambio pequeño. Después, el harness ejecuta la prueba definida. Por último, el agente solo puede iterar si la falla trae información nueva. Si el error no cambió, repetir es solo quemar contexto.
El loop también necesita memoria corta y memoria larga. La memoria corta guarda el error actual, el comando que falló y el diff que lo causó. La memoria larga guarda patrones del repositorio: estilo de pruebas, comandos canónicos, servicios externos y trampas conocidas.
No confundas la corrección automática con permiso para tocar todo. Un agente que modifica muchos archivos para que pase una prueba rota puede haber aumentado el riesgo, no reducido. El harness debe medir el tamaño del diff, la frontera de módulo y la relación entre prueba y requisito.
¿Qué gates deben bloquear el PR?
En 2026, la propia GitLab plantea el problema como código de IA que se genera más rápido de lo que las organizaciones logran controlar (GitLab, AI Accountability Report, 2026). Los gates de PR existen para invertir esa asimetría: la automatización solo acelera cuando también produce control.
El primer gate es la reproducción. Si era un bug, el PR debe mostrar la prueba que fallaba antes. Si era una feature, debe mostrar el comportamiento esperado y el límite negativo. Sin eso, el revisor se vuelve un detector manual de intención.
El segundo gate es la integridad del diff. El harness debe bloquear archivos fuera de alcance, la eliminación de pruebas sin justificación y cambios en el lockfile sin una dependencia relacionada. Esto atrapa muchas «soluciones» que solo empujan el problema a otro lugar.
El tercer gate es la evidencia operativa. Para el backend, esto puede incluir prueba de contrato, migración reversible, log estructurado y verificación de permisos. Para DevOps, puede incluir plan de infraestructura, política de rollback y ausencia de secretos en el diff.
<figure>
<svg viewBox="0 0 760 260" role="img" aria-label="Gates de verificación para PRs de agentes de código">
<rect width="760" height="260" rx="18" fill="#101820"></rect>
<g font-family="Arial, sans-serif" font-size="18" fill="#f7f7f7">
<text x="48" y="54">Flujo de bloqueo del harness</text>
<rect x="48" y="92" width="140" height="70" rx="10" fill="#1f6f78"></rect>
<text x="74" y="134">Alcance</text>
<rect x="230" y="92" width="140" height="70" rx="10" fill="#2a8f7a"></rect>
<text x="255" y="134">Pruebas</text>
<rect x="412" y="92" width="140" height="70" rx="10" fill="#b77f2a"></rect>
<text x="436" y="134">Riesgo</text>
<rect x="594" y="92" width="118" height="70" rx="10" fill="#4f6f9f"></rect>
<text x="621" y="134">PR</text>
</g>
<g stroke="#e7f6f2" stroke-width="4" fill="none" stroke-linecap="round">
<path d="M188 127 H230"></path>
<path d="M370 127 H412"></path>
<path d="M552 127 H594"></path>
</g>
</svg>
<figcaption>Fuente: síntesis editorial basada en los contratos de revisión descritos en este artículo.</figcaption>
</figure>¿Cómo se vuelve esto rutina de ingeniería?
En 2025, la encuesta de Stack Overflow mostró una adopción amplia de IA, pero también una caída de confianza en la precisión de las herramientas (Stack Overflow, Developer Survey AI, 2025). La buena rutina acepta esa tensión: usa agentes para reducir el trabajo repetitivo, pero exige evidencia antes de aceptar un cambio.
Empieza por una clase de tarea. Los bugs pequeños de backend suelen ser buenos candidatos, porque es posible exigir una prueba de reproducción. Después avanza hacia refactors localizados, mejoras de observabilidad y ajustes de CI. Evita empezar por una migración amplia o una regla de seguridad sensible.
El archivo de instrucciones del agente debe encajar en la rutina real del equipo. Tiene que decir cómo ejecutar las pruebas, cómo elegir archivos, cómo reportar un bloqueo y cómo evitar cambios fuera de alcance. Si nadie revisa ese archivo, se vuelve decoración.
También conviene llevar un diario corto por PR. No para burocracia. Para aprendizaje. ¿Qué fallas atrapó el harness? ¿Cuáles pasaron? ¿Qué se volvió un falso positivo? ¿Qué debería haber bloqueado y no bloqueó? Ese historial mejora el harness sin depender de la memoria informal.
FAQ sobre harness de agentes de código
¿El harness de agentes de código sustituye al code review humano?
No. En 2026, GitLab muestra que el 85% de los desarrolladores ve la revisión, la edición y las pruebas de código con IA como cuello de botella (GitLab, AI Accountability Report, 2026). El harness reduce el ruido antes del humano, pero las decisiones de producto, seguridad y arquitectura siguen siendo humanas.
¿MCP es obligatorio para este tipo de flujo?
No, pero ayuda cuando el agente necesita acceder a herramientas heterogéneas. En 2025, la especificación del Model Context Protocol describe herramientas, recursos y prompts como partes estandarizadas del contrato (Model Context Protocol, specification, 2025). Sin MCP, el mismo principio aplica: cada herramienta necesita permiso y prueba claros.
¿Cuál es el primer gate que vale la pena implementar?
Empieza por la prueba de reproducción. En 2025, Stack Overflow mostró que la confianza en la precisión de las respuestas de IA quedó en 29% (Stack Overflow, Developer Survey AI, 2025). Una prueba que falla antes y pasa después reduce el debate subjetivo sobre si el agente entendió el problema.
¿Los subagentes siempre mejoran el resultado?
No. En 2026, claude-blog solo vuelve productivo el fan-out porque combina sub-skills con contrato de entrega, revisión bloqueante y límite de iteración (AgriciDaniel, claude-blog, 2026). En código, los subagentes sin gate crean más opiniones para revisar.
Fuentes y lectura adicional
- GitLab, AI Accountability Report, consultado el 2026-06-28, https://ir.gitlab.com/news/news-details/2026/GitLab-Research-Reveals-Organizations-Are-Generating-AI-Code-Faster-Than-They-Can-Control-It/default.aspx
- Stack Overflow, Developer Survey AI, consultado el 2026-06-28, https://survey.stackoverflow.co/2025/ai/
- Anthropic, Introducing the Model Context Protocol, consultado el 2026-06-28, https://www.anthropic.com/news/model-context-protocol
- Model Context Protocol, specification 2025-06-18, consultado el 2026-06-28, https://modelcontextprotocol.io/specification/2025-06-18/
- OpenAI, Introducing Codex, consultado el 2026-06-28, https://openai.com/index/introducing-codex/
- AgriciDaniel, claude-blog, consultado el 2026-06-28, https://github.com/AgriciDaniel/claude-blog


